UVC decoder
Introduction
uvc的flow是一个较为固定的过程,可以硬件解码来降低CPU占用率。
整个flow可以分为独立的两部分,因此也由独立的两个电路实现:
UVC data decoder: 主要实现数据流的解码
UVC status controller: 主要实现对中断的控制,isoc in request的发起
USB FIFO 需求
根据已有的10个camera的描述符分析,FIFO需求如下:
For UVC+UAC composite device:
Endpoint
EP0 CTRL IN/OUT, for control transfer
EP1 ISOC IN, for MJPEG video stream
EP2 ISOC IN, for H264 video stream
EP3 ISOC IN, for audio stream
EP4 INTR IN, optional
Data FIFO (byte)
EP1 mps: 1024
EP2 mps: 1024
EP3 mps: 256
EP4 mps: 64
EP4是可选的,spec未规定大小,从已有camera的ep信息看,均为16。为匹配USB spec,intr fs最大mps设为64。
For ECM+ACM composite device:
Endpoint
EP0 CTRL IN/OUT, for control transfer
EP1 BULK IN, for ECM data in
EP2 BULK OUT, for ECM data out
EP3 INTR IN, for ECM notify message
EP4 BULK IN, for ACM data in
EP5 BULK OUT, for ACM data out
EP6 INTR IN, for ACM notify message
Data FIFO (byte)
EP1 mps: 512
EP2 mps: 512
EP3 mps: 64
EP4 mps: 512
EP5 mps: 512
EP6 mps: 512
已有的dongle设备,ecm的intr ep mps均为16,为匹配USB spec,intr fs最大mps设为64。acm的大多为16,有一个是512,所以就取了512。
需要DD参考以上内容,向RDC提USB的config form。
UVC的传输方式分析
UVC的video stream的基本结构如下

bulk传输
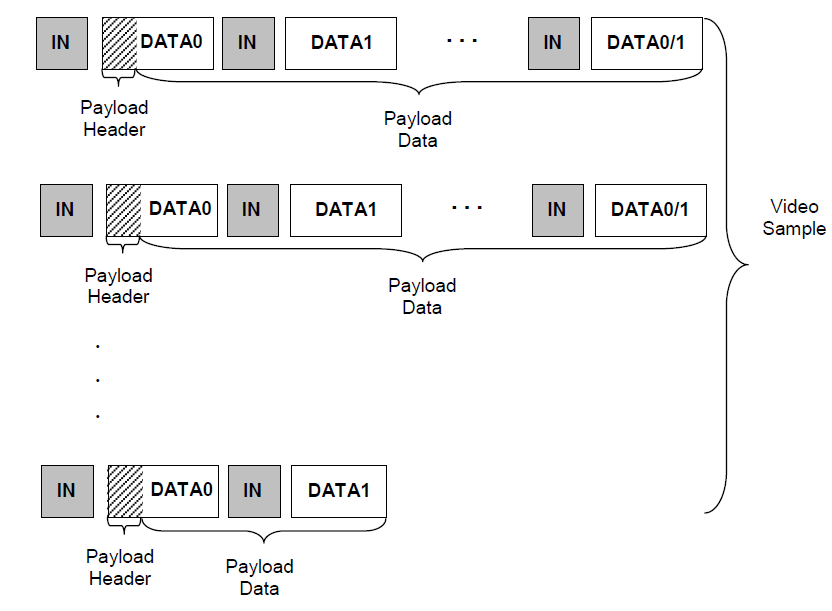
一帧通过多次bulk transfer完成
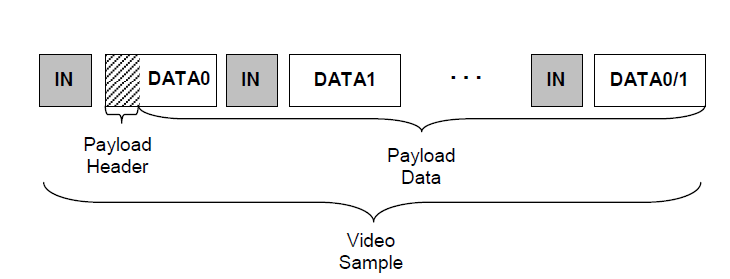
一帧由一次transfer完成
所以对于bulk传输,可以加大transfer size,在尽量少,甚至一个transfer内完成一帧的传输。
bulk传输并不多见,甚至一些系统都不支持这种camera。
没有相关camera,无法抓包判断实际是如何传的。应该是,host发in token后,device里有多少资料就传多少资料,不满512或者发一个zlp,认为是一个transfer结束。所以in token发的快,还是会有大量packet需要处理。
bulk这种传输方式,可以是低优先级或者不实现.
isoc传输
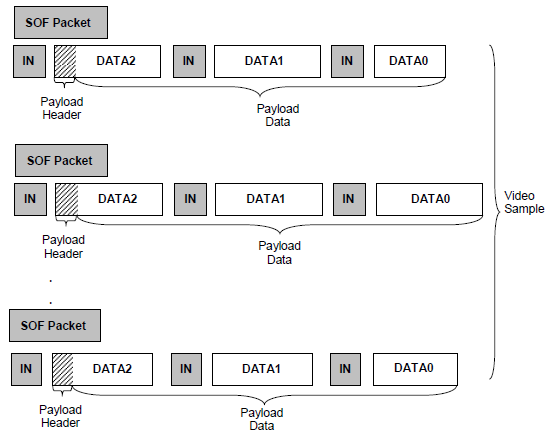
ISOC传输一个微帧内只有一个uvc header。对于USB2.0,一个微帧内可以是0-3个isoc packet,length最大为1024,只有第一个isoc packet有header。
UVC Data Decoder
UVC data decoder是一个处理数据的模块,这是因为uvc decode的过程是相对单纯的过程.
过程分析
对于门锁应用,需要三路stream,各需要占用一个host channel.预计USB host的使用方式如下(一小格为一个transfer,同颜色为同一帧).MJPEG最高需求为 1280*720 30fps. h264可能更高.

对于JPEG和H264(非simulcast)类型的header,uvc payload header格式如下(如果不是这个格式,就不是标准的)
offset |
field |
size |
description |
|---|---|---|---|
0 |
bHeaderLength |
1 |
header长度 |
1 |
bmHeaderInfo |
1 |
BIT0: FID.表示当前的frame ID,相邻frame的ID不同 BIT1: EOF.表示当前是否是一帧的结束. BIT2: PTS.表示是否有dwPresentationTime field,即时间戳. BIT3: SCR.表示是否有dwSourceClock field. BIT4: RES.不同的payload意义不同.忽略. BIT5: STI.表示后面的为抓取的静态图片数据.忽略. BIT6: ERR.表示传输错误. 如果此有效载荷的视频或静止图像传输出错. BIT7: EOH,表示是否负载数据头的最后一个字节.0表示头部没有结束,还可能有后续头部信息.1就表示当前header是本次transfer的最后一个header.对于uvc应用,由于header较短,基本都会在一个packet中传完,未发现EOH=0的情况,因此不考虑此bit. |
2 |
dwPresentationTime |
4 |
This is the source clock time in native device clock units when the raw frame capture begins. 即frame采样时的时间 |
6 |
scrSourceClock |
6 |
分为3部分
|
典型的stream流如下.同一个颜色为同一帧,通过FID或者EOF来区分.

而decoder要做的工作,就是代替SW解析上面的包.最主要的工作是,根据FID/EOF来确定属于哪一帧,并去除header,组成一个完整的帧给SW.
功能实现
UVC decoder应该处于的位置如下.它要能实现JPEG和h264这两路数据的解码.

它的功能包括:
可以关闭此功能,此时所有数据都bypass过去.
对MJPEG和H264两路数据解码.
可以传入buffer地址,对packet解码后,同一帧帧都放到该buffer里,完成后,上报一个complete中断.
可以进行错误处理,有错误,收完同fid的所有packet后,上报中断.
存在寄存器保存一帧的PTS和SCR的值.
可以配置两个用于pingpong的buffer地址来保证当前数据如果没有及时处理,前一帧不会被覆盖.
提供寄存器控制是哪个channel需要进行解码,不需要的直接bypass.
细节的参考flow如下:
步骤 |
行为 |
|---|---|
判断header length |
虽然spec规定length为12,但不排除不规范的camera,因此要通过PTS,SCR来判断长度.比如,如果PTS,SCR都为1,length需要为大于等于12,如果都为0,则判断大于等2.否则直接丢弃此packet. 如果难做,就不考虑不规范的camera. |
判断err |
如果error bit为1,收下所有同FID的packet后,只为中断状态寄存器的error bit.SW可以选择不开启这个中断,因为可能太多了. |
保存PTS |
在寄存器中保存PTS的值.spec规定同一帧图片,PTS的值相同,所以可以只处理第一个packet里的PTS. |
保存SCR |
寄存器保存一帧图片中第一个packet和最后一个packet的SCR的值. |
判断EOF是否设置 |
报compete中断完成了一帧传输,并切换buffer,这样可以保证较低的延时,因为如果用fid来确定complete中端,可能导致一帧时延. 但是因为有的camera没有eof,此时FID为准来切换buffer,如果HW不好做,就增加一个SW bit来控制是fid还是eof来控制complete中断. |
判断FID是否翻转 |
如果翻转,表示上一帧完成,切换到另一个buffer,报complete中断且当前packet切到另一个buffer(前提是没有EOF). |
组帧 |
将每个packet的payload的内容按顺序放到帧buffer中,寄存器保存total length,随着packet length递增. |
由于是两个相邻帧的FID不一样,应该要给两个frame buffer进行toggle,需要两个寄存器保存这两个addr的值.
时间戳的问题,有两种处理方法:
根据PTS等计算时间戳
在帧组装完成后,软件获取当前的系统时间.
影音同步的问题.据PC team反馈,他们不采用UVC协议里的时间戳,UAC本身也没有规定时间戳.UVC和UAC stream均是收下后,加上本地时间戳后进行处理.具体怎么加时间戳看软件协议.如果是他们的IPC用RTSP协议直接传到云端,就是在IPC里加上本地系统时间戳,然后传到云端.
SW使用步骤
步骤 |
行为 |
|---|---|
1 |
初始化USB |
2 |
初始化UVC,纯SW行为 |
3 |
枚举 |
4 |
设定接口,和camera协商好format,frame和altsetting |
5 |
分配和打开pipe,对应到HW就是init某个host channel |
6 |
init decoder,步骤如下(如果是两个channel另一个channel也这么做)
|
7 |
enable decoder,即uvc_concat_en写1 |
8 |
根据端点的binternal,在对应的sof中断里,发起isoc in传输.如果是两个channel,另一个也这么做(发起isoc in的flow参考 过程分析) |
9 |
传输完成后,处理中断(参考 过程分析) |
10 |
重复步骤8-9,除非停止收数据 |
11 |
decoder会将数据解码后,放到buf0里,满了之后报frame done中断.中断处理函数中,clear此中断,检查数据正确性.后续下一帧数据放到buf1里,如此反复. 如果两个channel,另一个channel行为也一样. |
12 |
一段时间后,停止发起isoc in传输,disable uvc_concat_en |
13 |
重复6-12的动作 |
关于pingpong buffer
UVC data decoder不需要关心递交frame后buffer的处理,它只需要保证:
在提供的两个buffer之间来回切换即可,其他的交由SW处理.
isoc in传输不能停止,否则camera可能会有错误.
SW可以通过多个buffer来保证frame可以被及时处理.比如fps为30,有三个buffer,则只需要33ms内及时处理该frame,且在frame done中端里,立刻修改当前首尾addr到空闲buffer就没有问题.另外一个角度,如果mjpeg和lcdc不能30ms内处理完这一帧,整体就达不到30fps,整个功能也实现不了.
UVC Status Controller
过程分析
前置操作由SW完成。usb初始化,枚举,协商,设定接口,open pipe等。这些操作是一次性的,不需要HW参与。
其中open pipe的flow:
将对应hc的中断状态请0,开启hcint部分中断,对于isoc in的channle,分别是xfercm,ahberr,frameoverrun
使能host中对应的channel num的中断 haintmsk,开启更上层的global中断寄存器 gintmsk 0的hc中断
配置HCCHAR的部分bit,包括端点类型,端点号,奇偶帧控制 每次传输会重新配,设备地址 只支持一个设备,默认为1,是否是low speed,端点方向,MC和MPS 后需要重新配置
其中奇偶控制即希望下一帧是偶数帧开始还是计数帧开始,为了能在下一帧开始,会直接读framenum加一算出下一帧是奇数帧还是偶数帧.
接下来的动作则是循环的,可以由HW控制.
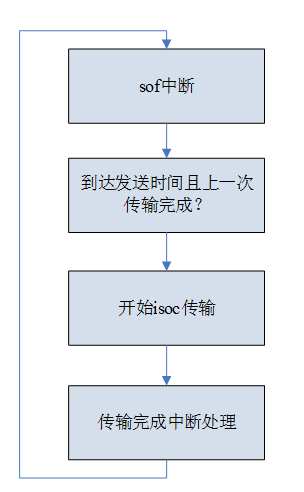
其中,sof中断是判断是否发起isoc in传输。它的判断条件是给定的interval到时间且上一次传输完成。
开启isoc传输:
配置hcchar寄存器,包括MC,奇偶帧控制,enable channel开始传输(最后做)
配置hctsiz寄存器,包括xfersize,number packets,data pid
配置hcdma寄存器,写入buffer地址
dache cleaninvalidate
中断处理 (注意,这个flow和programming guide上的flow不一样,但是实测可以跑):
读GINTSTS,判断中断是hc中断
读haint,确定是哪些channel发生了中断
读hcint,确定是什么中断,如果是xfercm中断,clear中断并计算长度后,告知线程urb done了
线程收到urb done消息后,获取长度,并将urb递交给decode线程
功能实现
UVC status controller的功能是代替上面描述的SW循环处理。它被设计为一个master,通过设定好的访问寄存器flow来实现此功能。但是flow中有一个问题, GINTST 是global寄存器,与别的端点共用 hcint 中断,无法直接判断该填何值。
UVC相关的HC中断是不是可以不开呢,这样就可以不用操作相关寄存器了?从SW测试可以得到,不开HAINT对应channel以及不开开hcintmsk的 xfer comp中断,传输完成后该位也会置位,而且可以被clear。DD check是可行的。
因此,UVC status controller具体功能包括:
有一个控制位,可以控制打开关闭此功能。
有一组寄存器,SW可以对其进行设定。使能后,通过如下一定的flow将设定的寄存器值写入到usb寄存器中。
获取USB的frame num信息,并根据SW填入的interval信息,在确保上一次已经complete的情况下,自行判断何时进行isoc in request的寄存器操作,然后按照一定的寄存器flow去读写寄存器。
获取USB设定host channel的的xfer comp信息,它置位的时候,去按一定的flow读写寄存器。

上述的flow寄存器的结构如下,每个flow由两个寄存器组成, REG1 用于表示寄存器的地址和行为, REG2 表示要写入的值。
REG1 |
REG1 |
REG1 |
REG1 |
REG2 |
|---|---|---|---|---|
Enable (Bit[31]) |
Type (Bit[30:28]) |
RSVD (Bit[27:16]) |
Offset (Bit[15:0]) |
Value (Bit[31:0]) |
0:disable 1:enable disable表示yin |
000b:SW。写入REG2的值即可 001b:HW1。HW要做第一种特殊处理。 002b:HW2。HW要做第二种特殊处理。 以此类推,特殊处理定义会在下面描述。 |
写入的寄存器相对OTG base的offset |
写入的值 |
上述flow从收到xfer comp信号开始处理,包含一下4组flow寄存器。
序号 |
USB寄存器 |
行为 |
|---|---|---|
1 |
HCINTn |
HW1: 等待xfer comp信号,触发后clear该信号,并且需要拉frame num,通过binterval,计算出下一个req应该发起的时间,到时间后结束。 |
2 |
HCDMA |
SW |
3 |
HCSIZ |
SW |
4 |
HCCHAR |
HW2: 写入REG2的值,其中oddframe bit需要HW自行计算值,然后填入寄存器 |
5 |
RSVD |
SW |
6 |
RSVD |
SW |
7 |
RSVD |
SW |
能否fix host channel
最好是不要fix host channel,保留灵活性。可以先出一版fixed hc的电路,后续需要dd和dv确认是否可行。
增加master导致的一致性问题
由于还有一个audio端点,还有一些无意义中断,因此在uvc传输过程中,cpu仍然需要取访问寄存器。由于新增了一个master,它在访问usb时,会阻塞cpu对寄存器的访问。这样可能会造成一致性问题,需要考虑其影响。
从上述flow看,只会处理HC相关的寄存器 (包括中断,HW不会处理global中断),理论上应该不会互相影响。
带宽分配的问题
参考 USB带宽 的分析和计算,每个微帧的有效传输时间是有限的,能够传输的微帧数量和大小也是有限的。理论上讲就不可能支持一个微帧内两个 1024*3 的端点传输。这点要还后面从PC提供的camera再分析了。
当前flow和programing guide不一致的问题
当前实测直接判断xfercomp也可以跑的,但实际上program guide中的flow不一样,它是先判断channel halt中断,然后再判断xfercomp。

看起来linux和old stack是遵从了spec。linux代码中,有如下区别:
每次传输前都会分配一个hc,也即hc的号可能不是固定的。
在hc init中,只开 channel halt 和 ahb error 中断,没有开 xfercomp 中断。
在hc的处理函数中,判断channel halt 中断,进其处理函数后,再判断hcint是否有 xfercom bit,再进xfercomp 处理函数。
综合来看,无论中间flow如何,最后都会看 xfercom bit,因此HW只看这个信号即可。
audio端点的配合
加上uvc status controller后,理论上uvc的部分可以不需要sof中断,但是audio也是isoc in端点,需要sof中断来控制时间
SW发起audio端点的isoc in传输的时候,假设uvc status controller也发起了,由于配置的hc不一样,不会引起寄存器冲突,但是要考虑此时微帧无法发起传输,它会不会在下一次满足条件的时候发起呢。
frame overrun
SW曾经报过 frame overrun 中断,不知道是怎么触发的,这个中断spec中也没有详细描述。
其他问题记录
USB寄存器访问速度
在ameba smart km4(333M)上测试,read 100次USB寄存器需要24us,平均一次240ns,有点慢。100ns是合理的。
优化方向
软件尽量少去操作寄存器,目前底层存在大量冗余的寄存器读写操作
HW优化读寄存器的速度
FIFO size的详细分析
现在fifo 1024*4,所有端点共用。
之前提的spec,data fifo是否满足要求?
For UVC+UAC composite device:
Endpoint
EP0 CTRL IN/OUT, for control transfer
EP1 ISOC IN, for MJPEG video stream
EP2 ISOC IN, for H264 video stream
EP3 ISOC IN, for audio stream
EP4 INTR IN, optional
Data FIFO (byte)
EP1 mps: 1024
EP2 mps: 512/1024
EP3 mps: 128/256
EP4 mps: 64
audio stream:
camera1 interval 4, mps 196*1
camera3 interval 4, mps 256*1
camera5 interval 4, mps 204*1
camera6 interval 4, mps 100*1
camera7 interval 4, mps 256*1
camera_haier in nterval 4 256*1
h264 stream:
camera7只有一个alt interface可以选, interval 1, mps 1024*2
camera3有很多
1280*720 30fps实测要求interval 1, mps 768*3
2560*1440 30fps,实测要求interval 1, mps 1024*3
H264是帧间编码,由少量的I帧(完整的jpeg图片),大量的P帧(前向预测编码)和B帧(双向差别帧)组成,P帧和B帧都很小,I帧比较大,因此H264的传输是不均匀的,I帧会比较大,因此其mps可能并不小。
实测如下图
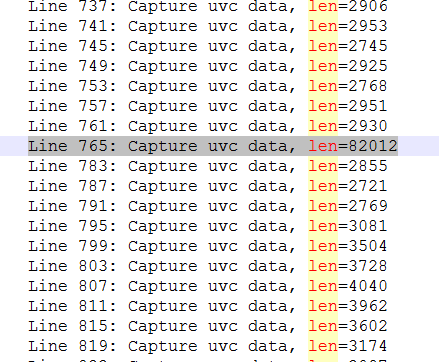
USB带宽
linux带宽控制,根据isoc端点的mc和mps,计算出它需要占用一个微帧内多少时间,再根据interval,计算它需要在哪些帧上面发送数据。根据每个isoc端点的数据去计算出一个map用于描述每个isoc的分布情况,这样就可以确定每一帧如何发
门锁应用,最多3个isoc in端点,不必如此复杂,因为通过计算,每个微帧内至多可以发7笔packet len为1024B的传输,理论上可以满足要求。因此直接按照各个端点其interval,在sof到来的时候,发送isoc传输即可。
可能1个微帧内发起多次不同端点的isoc传输吗?
需要向羽在7005上simulation一个微帧内多个端点传输
两个端点, 第一个
1024*3,第二个512*2三个端点,第一个
768*2,第二个512*2,第三个128*1
linux dwc driver对于非周期端点,它是直接入队发起传输,没有带宽分配的概念. 对于周期端点,则会根据端点的mps,mc,interval, 计算它需要在哪些微帧上面发送数据。提供了两种周期端点传输方法。
第一种是,发起一个isoc端点的传输,简单的计算一个微帧内是否有足够时间容纳这个isoc的传输。
一个微帧125us,有效带宽为100us。
初始化一个isoc端点,根据其mps和mc计算占用微帧内的有效时间,计算方法为,一个1024的packet计算得到21.5us,3072为60us。然后更新一个微帧的空余时间,将该端点的 next_active_frame 直接设为下一个frame。
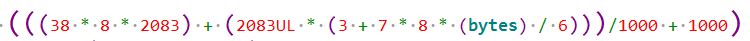
如果有更多的isoc端点,重复上述操作。如果空余时间不够,返回错误。
在sof中断中以及每笔周期端点的transfer comp函数中,获取当前的frame num,判断每个端点的 next_active_frame 是否
≤frame_num,满足则发起传输.
第二种是,根据每个isoc端点的数据去计算出一个map用于描述每个isoc的分布情况,这样就可以确定在哪一帧发什么请求。
以8个微帧,即1ms为单位,初始化一个map。其中,每个微帧有效的传输时间依然为100us。
加进来一个周期端点,根据它的mc和mps,计算它需要花费的时间(计算方法同上),并根据interval,以及下面描述符的算法,加在map上
每加进来一个周期端点你,重复上面的操作。
获取当前的frame num,根据map的内容,计算出每个端点应该在哪个frame执行,记为 next_active_frame
在sof中断中以及每笔周期端点的transfer comp函数中,获取当前的frame num,判断每个端点的 next_active_frame 是否
≤frame_num,满足则发起传输
上述 step2 and step3 的简化算法如下:
假设map长为8(对应8个微帧),宽为5 bit(实际为100,以1us为刻度)
加入第一个intv=2,占用时间为2bit的端点,它会分布在0,2,4,6的前两个bit处
加入第二个intv=3,占用时间为3bit的端点,由于interval为3,它可能在任意微帧内出现,而前2bit可能已经被占用,因此需要占据所有微帧的后3个bit
加入第三个intv=4,占用时间为1bit的端点,只有1,3,5,7有空余,选择1,5的第一个bit
第二个端点被disable,移出其占用的bit
以此类推
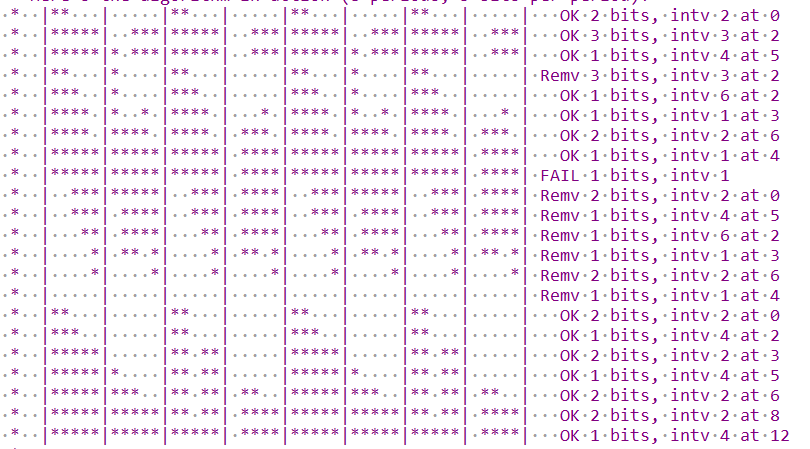
cpu占用
7MB/s的数据量。其中,decode线程的占用和之前的有出入,之前是9MB占用30+,不对齐的copy是40+。原因是
之前的数据,一次copy的length是随机的,实际测试发现数据会集中,即会有很多只有header的packet,不需要copy,要copy的length也更长了,花费的时间短。
实测发现所有的cam都是对齐的数据长度,这个之前就知道,但是PC team说不一定。
usb isr线程占用较多,主要花在
8000个sof中断
中断处理中大量读写寄存器,花费较多时间,需要优化
每次传输都要有dcache的操作
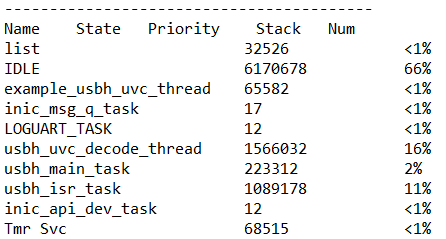
PSRAM带宽

1280*720*30*4=110MB
audio一般设定的最大值:
48khz*24bit=144kBH264 一般小于1MB
MJPEG按照15MB预估
JPEGDEC read MJPEG 15MB
JPEGDEC read OSD, 假设占据屏幕的1/10: 11MB
JPEGDEC write PSRAM,110MB
LCDC read PSRAM, 110MB
总: 110+110+11+15+16=262MB
几个关键点
从UVC到jpegdec,中间尽量不要有copy,这一点理论上是可以用多个frame buffer做到的 前提是jpegdec的处理速度够快 ,完成一帧后,丢给jpegdec处理
lcdc仍然采用双buffer处理,pp输出一帧后再切buffer。因此不需要额外的buffer copy过程。

