以太网
支持的芯片[ RTL8721F ]
概述
以太网(Ethernet)是一种遵循 IEEE 802.3 标准的有线网络连接技术。Ameba 系列芯片内部集成了符合 IEEE 802.3 标准的 MAC (Media Access Control) 控制器,并通过 RMII (Reduced Media Independent Interface) 接口连接外部 PHY (Physical Layer) 芯片,从而接入物理网络。

以太网架构示意图
功能特性
当前以太网模块支持以下关键特性:
接口标准与速率
支持 RMII 接口标准。
支持 10/100 Mbps 速率,支持全双工/半双工模式。
支持速率与双工模式的硬件自动协商 (Auto-negotiation)。
协议与流量控制
全双工模式:支持 IEEE 802.3x 流量控制 (Flow Control)。
半双工模式:支持 CSMA/CD (载波侦听多路访问/冲突检测) 协议。
工作模式与时钟
支持 RMII 接口配置为 MAC 模式 或 PHY 模式。
支持输出 25/50MHz 参考时钟源,可节省外部 PHY 晶振。
管理与高级功能
支持通过 SMI(MDC/MDIO) 接口配置和管理 PHY 设备。
支持 SMI Master (STA) 模式控制外部 PHY。
支持 EEE (Energy Efficient Ethernet) 节能以太网标准。
快速上手
通信接口
Ameba MAC 与外部世界的通信依赖两个核心接口:传输数据的 RMII 和配置管理的 SMI (MDC/MDIO)。

RMII 和 SMI 接口
RMII 数据接口信号
Ameba 芯片通过 RMII 接口与外部 PHY 芯片连接,以下是标准的信号定义及方向说明。
信号名称 |
缩写 |
方向 |
描述 |
|---|---|---|---|
TX Data 0 |
TXD0 |
MAC ➔ PHY |
发送数据位 0。MAC 传输给 PHY 的低位数据。 |
TX Data 1 |
TXD1 |
MAC ➔ PHY |
发送数据位 1。MAC 传输给 PHY 的高位数据。 |
TX Enable |
TX_EN |
MAC ➔ PHY |
发送使能信号。当该信号为高电平时,表示 TXD 数据有效。 |
RX Data 0 |
RXD0 |
PHY ➔ MAC |
接收数据位 0。PHY 传输给 MAC 的低位数据。 |
RX Data 1 |
RXD1 |
PHY ➔ MAC |
接收数据位 1。PHY 传输给 MAC 的高位数据。 |
RX Error* |
RX_ERR |
PHY ➔ MAC |
接收错误指示信号。当 PHY 检测到当前接收的数据帧存在错误(如编码错误)时,该信号为高电平。 |
CRS_DV |
CRS_DV |
PHY ➔ MAC |
载波侦听/数据有效复合信号。表示 PHY 正在接收数据且介质非空闲。 |
Ref Clock |
REF_CLK |
双向 |
50MHz 参考时钟。这是 RMII 同步操作的核心时钟。 |
备注
IEEE 802.3u 定义中确实包含了 RX_ERR(Receive Error)。当 PHY 检测到接收到的数据包有错误(比如编码错误)时,会拉高这个信号通知 MAC 层。 实际实现为了节省引脚(GPIO),很多嵌入式 SoC 的 MAC 控制器在 RMII 模式下并不使用硬件 RX_ERR 引脚。数据完整性校验完全依赖于以太网帧自带的 CRC/FCS 校验机制。
RMII 相较于标准 MII 接口,将数据总线宽度从 4 位减少到 2 位,引脚数量更少,更适应嵌入式应用场景。为了在减少数据线宽度的同时保持 100Mbps 的传输速率,必须提高时钟频率(从 25MHz 提高到 50MHz)。
RMII 接口信号使用 REF_CLK 进行同步,因此 MAC 和 PHY 的 REF_CLK 必须参考同一 clock 源,实际应用中,有如下 RFE_CLK 架构:
MAC 向 PHY 提供 REF_CLK :MAC 的 REF_CLK 设置为输出,PHY 的 REF_CLK 设置为输入
PHY 向 MAC 提供 REF_CLK :MAC 的 REF_CLK 设置为输入,PHY 的 REF_CLK 设置为输出
外部时钟源同时向 MAC 和 PHY 提供 REF_CLK :MAC 和 PHY 的 REF_CLK 都设置为输入
如下图所示:

REF_CLK 方向
具体方向设置还要参考时钟源方案,详见 PHY 时钟源选择。
SMI 管理接口信号
接口 SMI (Serial Management Interface),通常被称为 MDIO 接口,是一种用于以太网 MAC 子层与物理层 (PHY) 之间进行管理数据交换的简单两线串行接口,最高速率 2.5MHz。
MDIO 接口架构为主从式 (Master-Slave),包含以下两类实体:
STA (Station Management Entity - STA 管理实体)
通常集成于 MAC (Media Access Control) 控制器中。
作为总线主机 (Master),负责发起所有管理帧(读/写操作)并驱动时钟信号 (MDC)。
MMD (MDIO Management Device - MDIO 管理设备) / PHY
集成于以太网 PHY 芯片中。
作为总线从机 (Slave),响应 STA 的读写请求。
MDIO 接口由两根信号线组成:
信号名称 |
缩写 |
方向* |
描述 |
|---|---|---|---|
MDC |
MDC |
MAC ➔ PHY |
管理数据时钟 (Management Data Clock)。为 MDIO 数据传输提供时钟基准(通常 < 2.5MHz)。 |
MDIO |
MDIO |
双向 |
管理数据输入/输出 (Management Data Input/Output)。用于传输配置命令和状态数据。需外部上拉电阻 (通常 1.5kΩ)。 |
小技巧
非周期时钟 :MDC 不需要是连续的周期信号,STA 可以在帧传输之间停止时钟(保持高电平或低电平),PHY 必须支持这种静态操作
频率无关 :只要不超过最大频率限制 (2.5 MHz),接口可以在任意低速率下工作,可以用软件模拟 (Bit-Banging) MDIO 时序。
工作模式
以太网 MAC(Media Access Control)控制器与外部器件的连接方式取决于其工作模式。
MAC 模式
默认工作模式,CPU 集成 MAC,使用外部 PHY 芯片,连接方式如 MAC 连接外部 PHY 芯片 。在此模式下,Ameba 的 RMII 接口遵循标准 MAC 定义,用于连接外部的以太网 PHY 芯片。Ameba 负责驱动 TX 信号线,并通过 MDC/MDIO 接口管理外部 PHY。

MAC 连接外部 PHY 芯片
PHY 模式
在嵌入式系统设计中,经常存在两个具备 MAC 控制器的芯片(如 SoC 到 SoC,或 SoC 到以太网交换机芯片)位于同一块 PCB 上且距离极近的情况。在此类场景下,使用两颗 PHY 芯片进行互联会增加不必要的 BOM 成本、功耗及 PCB 面积。
传统连接方式:该方式需要额外的器件,如下图所示

传统连接方式
PHY 模式(即 MAC to MAC 直连模式):Ameba MAC 控制器可配置为
PHY 模式,连接示意图如 MAC to MAC 直连 。在此模式下可节省 PHY 芯片、变压器等器件,显著优化硬件架构。

MAC to MAC 直连
警告
PHY 模式注意事项
禁用自协商 :没有 PHY 芯片的参与,不能使用自协商,需要强制指定速率(Speed) 和双工(Duplex)。
交叉连接: 注意 TX/RX 线的交叉连接 (TX 接对端 RX)。
时钟同源:强烈建议采用同源时钟策略。即由其中一颗 SoC 输出 50MHz 给另一颗,或两颗 SoC 共用同一个外部晶振源,以避免因时钟频偏 (PPM) 导致的 FIFO 溢出或 CRC 错误。
引脚配置
ameba_intfcfg.c 文件预定义了 4 组以太网引脚配置( ETHERNET_PAD ),默认使用 Group 0。
引脚功能 |
Group 0 (默认) |
Group 1 |
Group 2 |
Group 3 |
|---|---|---|---|---|
RMII 接口信号 |
(固定组合) |
(固定组合) |
(固定组合) |
(固定组合) |
REF_CLK |
PB_9 |
PB_18 |
PB_30 |
PB_18 |
TXD0 |
PB_8 |
PB_13 |
PB_29 |
PC_4 |
TXD1 |
PB_7 |
PB_16 |
PB_28 |
PC_3 |
TXEN |
PB_6 |
PB_15 |
PB_27 |
PC_2 |
RXD0 |
PB_11 |
PB_21 |
PC_0 |
PC_7 |
RXD1 |
PB_10 |
PB_19 |
PB_31 |
PC_6 |
RXERR |
PB_4 |
PB_17 |
PB_25 |
PB_17 |
CRS |
PB_5 |
PB_14 |
PB_26 |
PC_5 |
管理与时钟接口 |
||||
MDC |
PB_12 |
PB_22 |
PC_1 |
PA_25 |
MDIO |
PB_3 |
PB_23 |
PB_24 |
PA_26 |
EXTCLK |
PA_12 |
PB_24 |
PA_12 |
PB_19 |
EXTCLK 用于向外部 PHY 芯片提供时钟,详见 PHY 时钟源选择 。
备注
RMII 接口下的所有管脚分配都是固定的,用户需要查询 pinmux 表,根据当前芯片封装修改
ameba_intfcfg.c文件中的变量ETHERNET_Pin_Grp(0x0 - 0x3), 选择某个可用的引脚组合。MDC, MDIO 和 EXTCLK 可灵活配置为其他引脚,用户可根据 pinmux 表修改。
PHY 时钟源选择
PHY 使用 Ameba 芯片内部时钟
如果 PHY 芯片支持外部时钟输入,用户可以通过引脚复用将某根 PIN 配置为 EXT_CLK_OUT 功能(即前一小节 引脚配置 中的 EXTCLK 引脚),使用 Ameba IC 输出 25MHz/50MHz 时钟输出到 PHY。此时 PHY 芯片无需单独的 XTAL。

备注
悬空 PHY 的 REF_CLK 引脚:如果 PHY 芯片使用 RTL8201F,则支持额外的电路连接方法。REF_CLK 可以连接到 PHY 的 XTAL2,PHY 的 XTAL1 连接到 GND 以节省 PHY 的 XTAL,如下图所示:
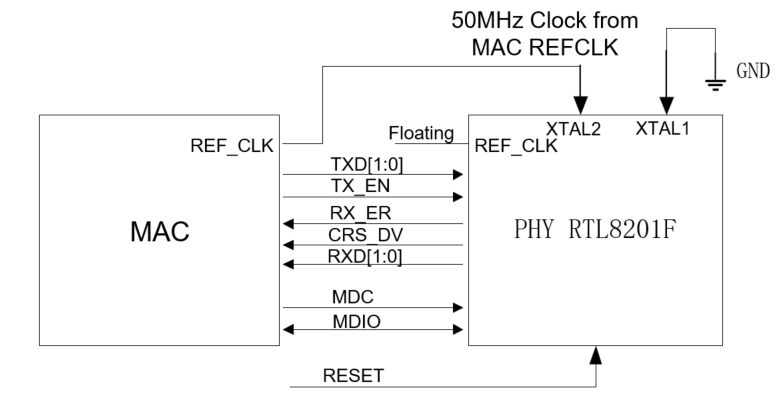
PHY 使用独立 XTAL
如果 PHY 的系统时钟由独立的 XTAL 提供,则不需要配置 EXT_CLK_OUT 。如下图所示:
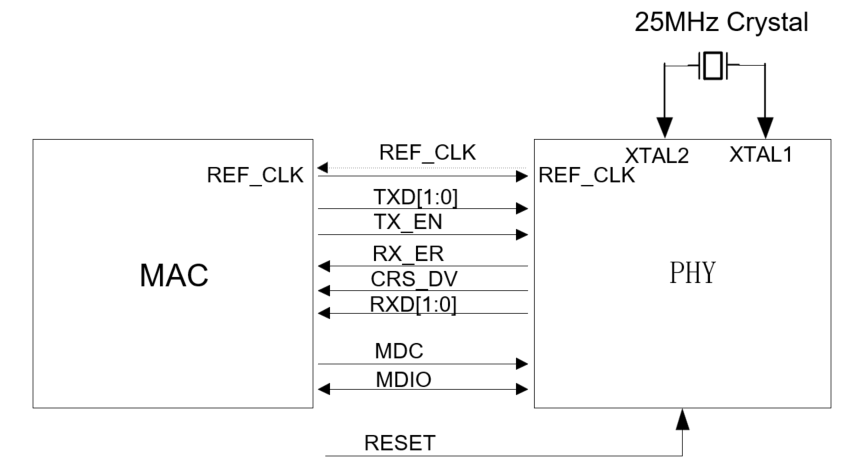
配置流程
Ameba SDK 集成了 LwIP 组件,实现了 MAC 层驱动(ameba_ethernet.c)和 PHY RTL8201F 的驱动(ameba_phy8201f.c)。在使用标准 EVB 开发板时,用户可根据以下流程配置并使用以太网。
Menuconfig 配置:编译工程前,需要通过
menuconfig启用相关组件。进入
CONFIG ETHERNET,使能 Ethernet。关键步骤:在
PHY SOURCE CLK中,根据当前板载硬件选择时钟源(详见 PHY 时钟源选择 )
如果 PHY 使用外部晶振:选择 ,保存后退出。
如果 PHY 使用 Ameba 芯片输出时钟:进入
PHY SOURCE CLK,选择 或者 ,保存后退出。
引脚与 PHY 适配
如果使用标准开发板,SDK 默认适配 PHY RTL8201F,可根据 EVB 开发板的型号查找原理图,修改文件
ameba_intfcfg.c中的ETHERNET_Pin_Grp索引值,选中当前开发板用到的数组ETHERNET_PAD[4][11]成员。如果使用自行设计的开发板以及其他 PHY 芯片,需要:
根据实际使用的引脚组合,修改文件
ameba_intfcfg.c中的ETHERNET_Pin_Grp索引值。根据实际使用的 PHY 芯片添加 PHY 驱动,可参考 PHY 接口适配 章节。
PHY 接口适配
软件架构
在了解 PHY 驱动适配之前,首先需要了解下以太网的架构分层。Ameba 以太网模块集成了轻量级 TCP/IP 协议栈(LwIP)和 MAC 驱动,其架构和 OSI、TCP/IP 模型的对应关系如下图所示:

以太网软件架构
各个层级功能如下表所示:
层级 |
组件 |
功能描述 |
核心源文件 |
备注 |
|---|---|---|---|---|
L5-7: 应用层 |
用户应用 |
实现用户业务逻辑及高层网络协议(如 HTTP, MQTT 等)。 |
(用户自定义) |
通过 Socket/Netconn API 交互 |
L4: 传输层 |
TCP & UDP |
提供端到端通信服务;TCP 负责可靠传输与流控制,UDP 提供低延迟数据报服务。 |
|
LwIP 标准核心 |
L3: 网络层 |
IP & ARP |
负责数据包路由、逻辑寻址(支持 IPv4/v6)以及物理地址解析。 |
|
LwIP 标准核心 |
L2: 数据链路层 |
LLC / 适配层 |
将 LwIP 的 |
|
移植适配层 |
MAC 驱动 |
直接操作 MAC 控制器寄存器,管理 DMA 描述符及以太网帧的发送与接收中断。 |
|
平台专用 (Ameba 硬件) |
|
L1: 物理层 |
PHY 驱动 |
配置外部 PHY 收发器芯片,管理自协商(Auto-negotiation)及链路状态检测。 |
|
平台专用 (外部芯片) |
硬件接口 |
MAC 控制器与 PHY 芯片之间的物理通信总线。 |
N/A |
RMII / MII 接口 |
备注
L2 层的 MAC 驱动及 RMII 接口操作在 SDK 中均已实现,并提供 RTL8201F 芯片的驱动(L1 层)。
适配步骤
用户如果使用其他 PHY 芯片,Ameba SDK 提供了灵活的 PHY 抽象层,允许用户适配不同的 Ethernet PHY 芯片。适配过程主要涉及实现 eth_phy_ops 接口表,并定义相应的设备实例。
实现 PHY 操作函数表
用户需要根据目标 PHY 芯片的数据手册 (Datasheet),实现 struct eth_phy_ops 中定义的关键函数。
备注
PHY 标准寄存器的定义,可参考
ameba_phy.h文件。PHY 芯片私有的寄存器定义,可直接定义在自定义的
ameba_phy_custom.c文件中,并将其添加到 CMakelists.txt。
以 RTL8201F 芯片为例,必要接口如下:
OPS 成员 |
对应实现函数 |
功能说明 |
必须性理由 |
|---|---|---|---|
|
|
初始化与 ID 校验 读取 PHY ID 寄存器并与 |
防止驱动匹配错误的硬件;确保 PHY 芯片已上电且 MDIO 通信正常。 |
|
|
软复位 写入 BMCR 复位位,并延时等待硬件稳定。 |
确保 PHY 处于已知的初始状态,清除之前的错误配置或状态。 |
|
|
参考时钟配置 切换 Page 7 设置 RMII 时钟方向(输入/输出)。 |
关键: RMII 接口必须同步 50MHz 时钟。如果方向配置错误(如 MAC 和 PHY 都在等待对方提供时钟),会导致物理链路根本无法建立。 |
|
|
链路参数配置 配置自协商(Auto-Neg)广播能力,或强制设置 Speed/Duplex。 |
决定 PHY 如何与对端交换机/路由器建立连接。未实现此接口会导致无法设置 10M/100M 或双工模式。 |
定义 Bus 接口与 PHY 实例
定义 MDIO 总线读写接口,并创建 eth_phy_dev 实例。在此处指定 PHY 的物理地址(Address)。
// 1. 定义 MDIO 总线操作接口
// 通常直接使用 SDK 提供的底层读写函数
const struct eth_mdio_ops eth_mdio_bus_default = {
.mdio_read = Ethernet_ReadPhyReg,
.mdio_write = Ethernet_WritePhyReg,
};
// 2. 定义 PHY 设备实例
struct eth_phy_dev eth_phy_dev_custom = {
.bus = ð_mdio_bus_default, // 绑定总线接口
.addr = 0x01, // 【重要】PHY 地址,需与硬件原理图一致
.ops = &custom_phy_ops, // 绑定步骤 1 中实现的操作表
};
注册并初始化
在以太网初始化阶段,调用 Ethernet_StructInit() 将定义好的 PHY 实例传入,完成驱动注册。
void User_Ethernet_Init(void)
{
ETH_InitTypeDef eth_initstruct;
// 使用自定义的 PHY 设备实例进行初始化
// 这会将 eth_phy_dev_custom 挂载到 MAC 驱动中
Ethernet_StructInit(ð_initstruct, ð_phy_dev_custom);
// 后续调用 Ethernet 其他函数
}
功能详解
自协商
自协商的主要功能是使物理链路两端的设备通过交互信息自动选择同样的工作参数,包括:
双工模式
运行速率
流控等参数
一旦协商通过,链路两端的设备就锁定在同样的双工模式和运行速率。
备注
百兆以太网标准:IEEE 802.3u 规范将自协商作为可选功能。
检测和识别机制
自协商主要通过物理链路上的脉冲信号或有序码组来实现。针对常见的 双绞线(电口) 环境,机制如下:
以太网自协商过程中,有两种脉冲:
NLP (Normal Link Pulse) : 主要用于 10BASE-T。仅用于检测链路是否连通(Link Beat),不包含速率信息。每隔 16ms ± 8ms 发送一个脉宽 100ns 的单脉冲。
FLP (Fast Link Pulse) :用于 100BASE-TX 和 1000BASE-T 自协商。它将 NLP 机制扩展为“脉冲簇(Burst)”。
结构:每个 FLP burst 簇同样每隔 16ms 发送一次,但包含了一组脉冲序列。
编码:每个突发簇包含 33 个脉冲位置(17 个时钟脉冲 + 16 个数据脉冲位置)。
间隔:时钟脉冲间隔为 62.5µs。数据脉冲位于两个时钟脉冲之间(表示逻辑 1),若该位置无脉冲则表示逻辑 0。
基础链路码字(Link codeword):一个 FLP burst 簇携带 16 位 (16-bit) 的链路码字,用于通告基本的速率和双工能力。

链路脉冲和链路码字
并行检测 (Parallel Detection)
当一方开启自协商,另一方不支持或关闭自协商(固定模式)时,开启方通过并行检测机制建立链路。
工作原理:开启自协商的端口同时检测 FLP、NLP 和 特征空闲码流。
检测到 NLP: 判定对端为 10M 设备。
检测到 4B/5B Idle 码流: 判定对端为 100M 设备。
警告
双工匹配限制: 并行检测 无法 获取对端的双工模式信息。根据标准,通过并行检测建立的链路,自协商端 必须 降级为 半双工 (Half-Duplex) 模式。
协商场景分析
链路能否建立及工作状态取决于两端的配置模式。
本端配置 |
对端配置 |
链路结果 |
结果说明 |
|---|---|---|---|
自协商 |
自协商 |
✅ 成功 |
双方交换能力集,锁定在共同支持的最高性能模式(如 100M 全双工)。 |
自协商 |
固定 10M/100M (半双工) |
✅ 成功 |
触发并行检测。自协商端自动匹配速率,并设为半双工。 |
自协商 |
固定 10M/100M (全双工) |
⚠️ 双工不匹配 |
物理链路 Link Up,但丢包严重。 自协商端通过并行检测设为 半双工,对端强制为 全双工。导致冲突报错 (Collision) 和 CRC 错误。 |
自协商 (仅全双工) |
自协商 (仅半双工) |
❌ 失败 |
如果双方能力集无交集(例如一端只支持全双工,另一端只支持半双工),无法建立 Link。 |
固定速率模式 A |
固定速率模式 B |
❌ 失败 |
若 A 和 B 速率或双工不一致(如 10M vs 100M),物理层无法同步,Link Down。 |
如果关闭自协商,则需要强制指定速率和双工等参数(例如强制 100M 全双工),并确保 PHY 和 MAC 参数配置相同。
备注
以下场景需要关闭自协商:
PHY 模式:如果 MAC 控制器需要连接外部 MAC,需要工作在 MAC 模式,此时不需要外部 PHY 芯片,强制指定速率和双工。
虚拟局域网 VLAN
传统局域网内的所有连接设备属于同一个广播域 (Broadcast Domain)。随着网络规模的扩大,这种扁平化架构面临严重的扩展性瓶颈:
广播风暴 (Broadcast Storm):广播报文(如 ARP 请求、DHCP 发现)在全网泛滥,消耗带宽和 CPU 资源,易导致网络拥塞甚至瘫痪。
安全隐患:所有节点均可截获广播数据,缺乏逻辑隔离。
VLAN(虚拟局域网)技术通过将物理网络划分为多个逻辑上隔离的广播域,各个 VLAN 之间默认无法直接通信。广播报文被限制在各自的虚拟域内,从而有效解决网络拥塞问题,同时增强了数据传输的安全性与隔离性。
如图 VLAN 应用场景 展示了两台交换机分别连接到不同企业的计算机,此时就可以将四台计算机划分到不同的 VLAN,实现对不同企业用户的隔离。

VLAN 应用场景
要使交换机能够分辨不同 VLAN 的报文,需要在报文中添加标识 VLAN 信息的字段—— VLAN tag (虚拟局域网标签)。
帧格式
IEEE 802.1Q 协议规定,在以太网数据帧的 源 MAC 地址 字段之后、协议类型 (EtherType/Length) 字段之前加入 4 个字节的 VLAN 标签。帧格式如下:

VLAN 帧格式
具体字段定义如下:
字段 |
长度 |
描述 |
|---|---|---|
TPID |
2 字节 |
Tag Protocol Identifier (标签协议标识符)
|
PRI |
3 比特 |
Priority (优先级)
|
CFI |
1 比特 |
Canonical Format Indicator (标准格式指示位)
|
VID |
12 比特 |
VLAN ID (VLAN 标识符)
|
由于 12 位 VID 仅支持 4096 个 VLAN,无法满足运营商网络需求。QinQ 标准通过增加一层 802.1Q 标签扩展空间:
STAG (Service Tag):外层标签,由运营商管理。
CTAG (Customer Tag):内层标签,由用户侧交换机管理。
在 VLAN 交换网络中,依据帧结构的不同,数据帧主要分为以下两种形式:
有标记帧 (Tagged Frame):在原始以太网帧头中插入了 4 字节 VLAN 标签 (Tag) 的帧。
无标记帧 (Untagged Frame):未携带 VLAN 标签的原始以太网帧。
以太网链路根据连接对象的不同,划分为接入链路与干道链路:
接入链路 (Access Link) :连接用户终端(PC、服务器)。仅承载 1 个 VLAN,传输 Untagged 帧。
干道链路 (Trunk Link):连接交换机或路由器。承载 多个 VLAN,传输 Tagged 帧。
VLAN 帧处理机制
交换机内部在处理数据帧时,逻辑上统一按 Tagged 帧 处理。针对接入链路(Access Link)与用户终端交互的具体流程如下:
入方向 (Ingress) - 接收帧:
当交换机从用户终端接收到无标记帧 (Untagged) 时:
交换机依据端口配置(通常为 PVID),为该帧添加对应的 VLAN 标签。
重新计算帧校验序列 (FCS)。
将封装好的 Tagged 帧通过干道链路转发或进行内部交换。
出方向 (Egress) - 发送帧:
当交换机向用户终端发送数据前:
交换机识别出目标端口为接入链路。
去除数据帧中的 VLAN 标签 (Tag Stripping)。
将还原后的无标记帧 (Untagged) 通过接入链路发送给用户终端。
VLAN 配置
Ameba MAC 硬件支持 VLAN 标签的卸载(Offload)处理,允许在数据发送(TX/Egress)和接收(RX/Ingress)阶段自动处理 VLAN 标签。
备注
硬件限制:
硬件仅支持识别双层标签结构(STAG + CTAG),不支持处理三层及以上嵌套的 VLAN 标签(Triple VLAN Tag)。
支持出向标签操作:每次仅能对单个标签执行插入/移除/重标记。
支持入向标签剥离:仅支持移除内层 CTAG,且剥离后的标签信息存储于 RX 状态描述符。
出向报文配置 (Egress/TX)
在数据发送方向,硬件可对报文中的 VLAN 标签执行动态修改。配置步骤如下:
配置操作对象与类型:由于支持双层标签(QinQ),驱动需告知硬件具体操作哪一层标签,以及该标签的协议类型。
配置出向动作:决定网卡在将报文发送到物理线路前,如何处理 VLAN 标签。
配置参数 |
详细描述 |
|---|---|
|
操作对象选择 (映射至 指定上述“插入/移除/重标记”动作作用于哪一层标签:
|
|
STAG 协议标识符 (映射至 仅当
|
|
目标 VLAN ID 当动作为 INSERT 或 REMARK_VID 时,硬件将使用此值作为新的 VID (0-4094)。 |
|
出向动作 配置出向动作,确定 MAC 如何处理 VLAN 标签。 |
备注
STagPID 限制:不可配置为 0x0800 (IP) 、 0x0806 (ARP)等字段。
其中 DefTxAction 有以下几种选项:
行为模式 |
功能说明 |
典型应用场景 |
|---|---|---|
保持原样 (Intact) |
不对报文做任何修改(支持双标签透传)。 |
|
插入 (Insert) |
在报文中插入一个新的标签。 (注意:插入后总标签数不能超过硬件支持上限,通常为 2 层) |
|
移除 (Remove) |
删除报文指定位置的一个标签。 |
|
重标记 (Remark) |
保留原有 Tag 结构,仅替换 VID 值。 |
|
配置建议:
普通上网场景:通常使用
INTACT,由操作系统的网络协议栈负责打标。嵌入式网关/路由场景:如果 CPU 负载较高,建议使用
REMOVE(针对 LAN 口) 和INSERT(针对 WAN 口) 来利用硬件卸载能力。
配置寄存器
VLAN_REG.tdsc_vlan_type:
1:操作对象为 STAG(外层标签)
0:操作对象为 CTAG(内层标签)
VLAN_REG.stag_pid:
可自定义 STAG 的协议标识符(其值不可為 0x0800, 0x8899。默认 0x8100)
入向报文配置 (Ingress/RX)
在数据接收方向,硬件主要负责标签的识别与剥离。关键配置参数如下:
RxStrip:接收剥离控制 (对应COM_REG.rxvlan)1: 开启硬件剥离。驱动需从 RX 描述符中读取 VLAN ID。0: 关闭硬件剥离。驱动接收到的数据包包含完整的 VLAN Tag 头。
节能以太网 EEE
节能以太网(Energy Efficient Ethernet,EEE)是一种基于 IEEE 802.3az 协议的电源管理技术。其核心机制被称为低功耗空闲 (Low Power Idle, LPI)。该技术允许网络设备在链路建立(Link-up)但无数据传输的空闲间隙,通过协议交互进入低功耗状态,从而显著降低能源消耗。
系统架构
EEE 功能需要 MAC 层(包含 LPI Client)和物理层 (PHY) 协同工作。

节能以太网架构
LPI Client(策略发起者)
通常位于 MAC 层。负责根据流量负载情况发起 LPI 请求。触发 LPI 的具体实现取决于具体厂商。
PHY(物理层)
负责对 xMII 信号进行编码(如 4B/5B 或 8B/10B),并通过物理线路与链路伙伴(Link Partner)交互。
进入/退出 LPI
标准 RMII 接口定义中移除了 MII 接口的 TX_ER 引脚,无法直接通过标准 IEEE 802.3az 信号组合进入 LPI 模式。其进入与退出
LPI 的状态由控制信号( TX_EN / CRS_DV)与数据总线( TXD[1:0] / RXD[1:0])的组合实现。 图 发送/接收路径进出 LPI 是 RMII 进出 LPI 的时序信号。

发送/接收路径进出 LPI
发送路径 (TX LPI):MAC 决定何时让 PHY 进入或者退出退出省电模式
进入 LPI :MAC 驱动
TX_EN=0,TXD=01,PHY 侦测到此状态后,关闭模拟发送电路。保持 LPI :MAC 维持
TX_EN=0,TXD=01退出 LPI :当 MAC 需要发送数据或定时器到期时,MAC 将
TXD[1:0]从01恢复为00(此时TX_EN仍为 0)。 这代表 "Wake Request"。经过必须的唤醒时间 Twq 后,MAC 拉高 TX_EN 开始传输数据
接收路径 (RX LPI): PHY 侦测链路对端状态并通知 MAC 进入或者退出省电模式
进入 LPI :PHY 从线路上检测到对端发送的 LPI 信号。PHY 将
CRS_DV拉低,并将RXD[1:0]驱动为01。 MAC 侦测到CRS_DV=0,RXD=01后,进入 RX 低功耗模式保持 LPI :PHY 维持
RXD[1:0]为01,直到线路状态改变退出 LPI :PHY 检测到线路上出现 IDLE 码流(唤醒信号),将
RXD[1:0]从01变回00。 MAC 识别到RXD变回 00,恢复接收时钟和解码逻辑,准备接收随后的数据帧
当检测到 xMII 接口上的 “Assert LPI” 信号时,PHY 的工作流程如下:

LPI 状态
休眠 (Sleep):本地 PHY 发送 SLEEP 码组通知对端。
静默 (Quiet):
通用:发送 SLEEP 后停止发送信号。
1000BASE-T:需等待对端也回复 SLEEP 后才共同进入 Quiet 状态。
刷新 (Refresh):在 Quiet 期间周期性发送 Refresh 信号,用于维持链路参数(如均衡器系数、时钟同步)。
唤醒 (Wake):发送 Wake 信号通知对端恢复正常工作模式。
LPI 决策机制 (Decision Makers)
TX 路径
进入 LPI 模式:MAC 内部通过以下决策器逻辑判断何时在 TX 路径上发起 LPI 请求(即输出
01编码):
硬件自动模式 :
发送队列空:当发送队列中最后一个数据包发送完毕,且无新数据包到达时,立即触发进入 LPI。
发送速率低于设定阈值:即使队列非空,如果当前发送流量速率(Packet Rate)低于设定阈值,MAC 可选择进入 LPI 并在缓存中积攒数据包,以减少频繁唤醒带来的开销。
接收暂停帧:当收到对端发送的 Flow Control Pause 帧时,MAC 暂停数据发送。在此等待期间,MAC 可自动进入 LPI 状态以节能。
软件强制模式:
软件通过配置寄存器强制 MAC 进入 LPI 模式,通常用于调试或特殊电源管理策略。
退出 LPI 睡眠模式:
硬件自动唤醒:
TX 队列有新数据包进入:硬件立刻触发唤醒序列
高优先级队列有数据:硬件立刻触发唤醒序列
软件强制唤醒:
软件层预知将有大量数据爆发(Burst),为了避免硬件唤醒的延迟(Wake-up Latency),软件可以提前设置 MAC 离开 LPI 状态,无论当前队列是否达到硬件唤醒阈值
RX 路径
RX LPI 的状态主要由 PHY 决定,MAC 处于被动配合状态。MAC 通过检测 RMII 接口信号变化来管理内部 RX 电路的功耗。
进入 LPI 模式:MAC 识别到
CRS_DV=0&RXD=01时,MAC 内部 RX 时钟域逻辑停止工作,停止解析数据包,进入低功耗状态。退出 LPI 模式:PHY 检测到线路上有 IDLE 流或数据流,驱动
RXD[1:0]从01变回00。
配置流程
配置流程如下:
关键前置步骤
自协商 (Auto-Negotiation): 必须开启。EEE 能力通过自协商的 Next Page 机制与对端交换。
全双工 (Full Duplex): 必须工作在全双工模式下。
PHY 支持: 连接的 PHY 芯片及网线对端设备 (Link Partner) 均需支持 EEE。
休眠/唤醒策略配置
休眠策略决定了 MAC 控制器何时主动发起进入低功耗状态 (LPI) 的请求。请根据应用场景选择合适的策略。
唤醒策略决定了 MAC 何时退出低功耗状态。
选项 |
描述 |
适用场景 |
|---|---|---|
|
立即休眠 (默认推荐) 一旦发送队列为空,立即请求进入休眠。 |
绝大多数 IoT 场景 功耗最低。但如果流量断断续续,会导致 PHY 频繁切换状态。 |
|
流量阈值控制 仅在发送流量低于设定阈值时才进入休眠。 |
对延迟敏感的场景 避免在数据包间隙极短时频繁休眠。 |
|
流控休眠 仅在收到流控 PAUSE 帧停止发送期间进入休眠。 |
高吞吐量场景 特殊场景,由流控机制触发节能。 |
选项 |
描述 |
推荐设置 |
|---|---|---|
|
任意数据唤醒 只要有数据写入发送缓冲区,立即唤醒 PHY。 |
Default 最安全、最通用的设置。 |
|
高优先级唤醒 普通数据在缓冲区排队,只有检测到高优先级数据包时才唤醒发送。 |
QoS 场景 仅在启用了 VLAN QoS 或特定优先级队列管理的复杂网络中使用。 |
流量门限调节
用于微调自动休眠的触发灵敏度。
参数:
TrafficThresholdLevel(范围: 0 - 100)推荐值:
50(默认平衡值)数值说明:
数值越小 (接近 0): 判定越激进,更容易进入休眠(认为当前是低负载)。
数值越大 (接近 100): 判定越保守,只有在极低流量下才休眠。
备注
此参数仅在 休眠策略 (Sleep Policy) 设置为 ETH_EEE_SLEEP_LOW_TRAFFIC 时有效。在其他模式下,该配置将被忽略。
测试模式
为了方便硬件调试和生产测试,当前 MAC 支持以下环回(Loopback)模式:
二进制值 |
宏定义 |
模式名称 |
功能描述 |
|---|---|---|---|
|
|
Normal Operation |
正常工作模式,数据正常收发。 |
|
|
R2T Mode (External Loopback) |
接收转发送 (外部回环)。 硬件直接将接收到的 RX 数据包转发到 TX 发送出去。 适用于测试外部物理线路连通性。 |
|
|
T2R Mode (Internal Loopback) |
内部本地回环。 CPU 发送的数据不经过 PHY,直接在 MAC 内部回传给 RX 接收。 适用于驱动开发、中断测试及 MAC 内部逻辑自测。 |

环回测试模式
T2R Mode: 数据在 MAC 内部直接环回,不经过 PHY。用于验证 MAC 控制器本身逻辑。
R2T Mode: 外部以太网数据发送到 PHY 后,在 PHY 内部(MII/RMII 接口侧)环回给 MAC。用于验证 MAC 到 PHY 的连接(如 PCB 走线、焊接)。
以太网描述符
以太网描述符是 软件驱动 (Driver) 与 以太网硬件 (DMA 控制器) 之间通信的核心共享内存结构。它本质上是一组结构化的内存块,用于描述网络数据包在物理内存中的 地址、长度 及 状态。
其核心设计目标是实现 Zero-Copy (零拷贝) 和 CPU Offload (CPU 减负):CPU 只需更新描述符中的指针和标志位,繁重的内存搬运工作完全由 DMA 负责。

描述符和缓冲区
备注
硬件与一致性要求
内存属性:TX 和 RX 描述符应放置在 SRAM Non-cacheable 区域 (或配置了 MPU 属性的 DDR),以确保 CPU 和 DMA 看到的描述符状态严格一致,避免 Cache Coherency 问题。
地址对齐:RX 描述符指向的数据缓冲区地址必须满足硬件要求的 4 Bytes (Word) 对齐,以支持 DMA 突发传输。
发送 (TX) 和接收 (RX) 各维护一组描述符链表,通常以 Ring Buffer (环形队列) 形式组织:
发送方向 (TX):
CPU 将数据封装到缓冲区,将缓冲区地址填入描述符,并置位 OWN 标志。DMA 检测到该标志后,自动从内存读取数据写入 TX FIFO 发送。
接收方向 (RX):
DMA 持续监控 RX 描述符。一旦 RX FIFO 收到数据,DMA 将其写入当前空闲描述符指向的缓冲区,并在写入完成后翻转 OWN 标志,触发中断通知 CPU 处理。
描述符格式
当前以太网支持的发送和接收描述符格式如下:

描述符格式
1. OWN (Ownership Bit) - 控制权归属 这是软硬件握手的核心标志(位于 Word 0 的最高位):
OWN = 1 (DMA 拥有):
表示 CPU 已经准备好数据(TX)或分配好空闲缓冲(RX),将控制权移交给 DMA。此时 CPU 不应 修改该描述符内容。
OWN = 0 (CPU 拥有):
DMA 完成数据搬运后,硬件自动将此位清零。表示 CPU 可以回收已发送的缓冲区(TX)或读取新接收的数据(RX)。
2. EOR (End of Ring) - 环形结束标志 用于指示当前描述符是否为环形队列的最后一个:
EOR = 1: 表示这是列表末尾。DMA 处理完此描述符后,内部指针将自动回绕(Wrap around),跳转回描述符基地址寄存器指向的 列表首部。
EOR = 0: DMA 处理完后,自动处理下一个连续地址的描述符。
描述符配置
单个缓冲区大小(buffer size)配置 :每个描述符指向一段内存缓冲区。为容纳带 VLAN 标签的最长标准以太网帧,通常计算如下:
ETH_HEADER_LEN + ETH_VLAN_TAG_LEN + ETH_PAYLOAD_MAX_LEN + ETH_CRC_LEN = 1522,考虑到跟 cache line 对齐(默认 32Bytes),最终大小为 1536Bytes。描述符数量设置 :
ETH_RxDescNum :接收描述符数量,数量越多,抗突发流量能力越强,但占用的内存越多。
ETH_TxDescNum :发送描述符数量
性能数据参考
测试基于以下系统资源分配与网络协议栈参数:
存储布局:代码执行段位于 PSRAM,描述符(Descriptors)位于 SRAM 无缓存(No-Cache)区域。
TCP 参数:接收窗口大小(TCP Window)配置为 23360 Bytes (16 × 1460 MSS)。
UDP 参数:发送延时(Delay)设置为 0。
缓冲配置:单个网络包 Buffer 大小设置为 1536 Bytes。
下表列出了在 100Mbps 和 10Mbps 速率下,分别处于全双工(Full-Duplex)与半双工(Half-Duplex)模式时的 UDP/TCP 吞吐量性能:
链路模式 |
UDP TX |
UDP RX |
TCP TX |
TCP RX |
|---|---|---|---|---|
100Mbps Full-Duplex |
95.4 |
93.5 |
94.8 |
78.0 |
100Mbps Half-Duplex |
95.4 |
92.0 |
90.0 |
78.0 |
10Mbps Full-Duplex |
9.60 |
9.57 |
9.50 |
9.49 |
10Mbps Half-Duplex |
9.54 |
9.57 |
8.80 |
8.90 |
注:数据基于标准测试环境,仅供参考。

